

Abstract
How does the visuomotor system decide whether a target is moving or stationary in space or whether it moves relative to the eyes or head? A visual flash during a rapid eye–head gaze shift produces a brief visual streak on the retina that could provide information about target motion, when appropriately combined with eye and head self-motion signals. Indeed, double-step experiments have demonstrated that the visuomotor system incorporates actively generated intervening gaze shifts in the final localization response. Also saccades to brief head-fixed flashes during passive whole-body rotation compensate for vestibular-induced ocular nystagmus. However, both the amount of retinal motion to invoke spatial updating and the default strategy in the absence of detectable retinal motion remain unclear. To study these questions, we determined the contribution of retinal motion and the vestibular canals to spatial updating of visual flashes during passive whole-body rotation. Head- and body-restrained humans made saccades toward very brief (0.5 and 4 ms) and long (100 ms) visual flashes during sinusoidal rotation around the vertical body axis in total darkness. Stimuli were either attached to the chair (head-fixed) or stationary in space and were always well localizable. Surprisingly, spatial updating only occurred when retinal stimulus motion provided sufficient information: long-duration stimuli were always appropriately localized, thus adequately compensating for vestibular nystagmus and the passive head movement during the saccade reaction time. For the shortest stimuli, however, the target was kept in retinocentric coordinates, thus ignoring intervening nystagmus and passive head displacement, regardless of whether the target was moving with the head or not.
Introduction
To maintain a stable visual representation despite self-motion, the visuomotor system should account for intervening movements of eyes and head. Because the original retinocentric coordinates of a target are not appropriate after self-motion, they need to be updated (“spatial updating”). The system could adjust its internal representations through extraretinal sources, such as vestibular signals, muscle proprioception, efference copies, or corollary discharges (Crapse and Sommer, 2008).
Humans (Hallett and Lightstone, 1976; Becker and Jürgens, 1979; Goossens and Van Opstal, 1997a; Vliegen et al., 2005) and monkeys (Van Grootel, 2010) accurately orient to brief visual flashes in the double-step paradigm despite an intervening saccadic eye, or eye–head gaze shift. Interestingly, spatial updating does not require visual-evoked programming of the intervening saccadic gaze shift. For example, when eliciting a saccade by microstimulation of the superior colliculus, the subsequent saccade to an extinguished flash is still goal directed (Mays and Sparks, 1980; Sparks and Mays, 1983). Long-latency saccades toward brief flashes presented before (Herter and Guitton, 1998) or during (Blohm et al., 2003; Daye et al., 2010) smooth-pursuit eye movements remain accurate, and also saccades to brief head-fixed flashes appear to incorporate eye movements caused by passive vestibular nystagmus (Van Beuzekom and Van Gisbergen, 2002).
Localizing a stimulus requires the visuomotor system to dissociate self-motion from target motion. Whereas extraretinal signals may provide accurate estimates of head-in-space and eye-in-head movements, retinal signals could provide information about target movement with respect to the eyes. But how much retinal motion is needed to decide whether a target is stationary in space or moves relative to the eyes, head, or body? What is the prior assumption about the stimulus reference frame when retinal-motion information is insufficient?
To answer these questions, we investigated the role of retinal input and the vestibular canals in spatial updating. We rotated head- and body-fixed subjects sinusoidally around an earth-fixed vertical axis, while they localized visual flashes that were either stationary in space or moved with the head. The experiments excluded the use of neck-proprioception and efference copies of head movements, so that only brief retinal motion signals, intervening eye-movements, and vestibular head-movement information during the saccade reaction time remained for updating target coordinates. We analyzed flash-evoked gaze shifts (ΔG) according to models (Fig. 1A) that differ in the compensation of intervening eye and head movements:
 with TR the initial retinal location of the target flash, ΔHS the vestibular-induced passive head-in-space movement during the reaction time, and ΔEH the eye-in-head displacement. For example, accurate localization of stationary stimuli in world coordinates requires full compensation of eye and head displacements (b = c = 1). Localization in retinal coordinates (no compensation) corresponds to b = c = 0, whereas spatial updating into head-centered coordinates, appropriate when stimuli move with the head, only incorporates eye-in-head displacement (b = 0, c = 1). Our results demonstrate that spatial updating depends on the reliability of target-motion information across the retina, because subjects adequately remapped the target location into head-centered (head-fixed targets) or world-centered (world-fixed targets) coordinates for long-duration stimuli only. In contrast, responses to very short flashes (0.5 ms) were best described in retinocentric coordinates (no spatial updating), regardless of whether targets were head or world fixed.
with TR the initial retinal location of the target flash, ΔHS the vestibular-induced passive head-in-space movement during the reaction time, and ΔEH the eye-in-head displacement. For example, accurate localization of stationary stimuli in world coordinates requires full compensation of eye and head displacements (b = c = 1). Localization in retinal coordinates (no compensation) corresponds to b = c = 0, whereas spatial updating into head-centered coordinates, appropriate when stimuli move with the head, only incorporates eye-in-head displacement (b = 0, c = 1). Our results demonstrate that spatial updating depends on the reliability of target-motion information across the retina, because subjects adequately remapped the target location into head-centered (head-fixed targets) or world-centered (world-fixed targets) coordinates for long-duration stimuli only. In contrast, responses to very short flashes (0.5 ms) were best described in retinocentric coordinates (no spatial updating), regardless of whether targets were head or world fixed.

A, Four models for visuomotor spatial updating during passive whole-body rotation. At time = 0 a visual target (TR) is presented while the subject fixates at F. During the response reaction time, the head (and body) is passively rotated (ΔHS). Because of vestibular nystagmus and absence of visual landmarks, the eyes undergo an eye displacement (ΔEH) and end at location F′ in the world. Model I predicts a response in world-centered coordinates and fully incorporates intervening head and eye displacements. Model II predicts a head-centered response because it incorporates only the change in eye position. Model III only accounts for the head displacement, whereas model IV keeps the target in the initial retinocentric reference frame. B, Temporal order of chair position, visual target, and eye movements.
Materials and Methods
Subjects
Six subjects (three of either sex) participated in the experiments. Three participants (the authors, one male, two female) were familiar with the purpose of the experiments. All subjects had normal or corrected-to-normal vision, except for JO, who is amblyopic in his right, recorded eye. Experiments were conducted after obtaining full understanding and written consent from the subject. The experimental procedures were approved by the Local Ethics Committee of the Radboud University Nijmegen and adhered to The Code of Ethics of the World Medical Association (Declaration of Helsinki), as printed in the British Medical Journal of July 18, 1964.
Apparatus
Vestibular setup.
Experiments were conducted in a completely dark room. The subject was seated in a computer-controlled vestibular stimulator (Van Barneveld and Van Opstal, 2010), with the head firmly stabilized in an upright position with a padded adjustable helmet. We measured chair position with a digital position encoder at an angular resolution of 0.04°. The present study used sinusoidal yaw rotation with an amplitude of 70° at a frequency of ⅙ Hz, which corresponded to a peak chair velocity of 73°/s. This rotation profile was applied using a custom-made Matlab program on a personal computer (Precision T3400; Dell Computer Company) that controlled a second personal computer that steered the position of the chair.
Visual stimuli.
The same Matlab program also controlled the visual stimuli via a PCIE-2214 card (Pericom). Visual stimuli emanated from an array of red light-emitting diodes (LED type HLMP-3301), with a response speed of 90 ns. LEDs were positioned on the intersections of seven concentric circles at viewing angles of 5, 10, …, 35° (at a distance to the cyclopean eye of 39 cm) and 12 directional meridians placed at every 30°. The visual stimulus array was either attached to the vestibular chair (head-fixed condition) or stationary in space (world-fixed condition). For comfortable positioning of the head, the center LED was positioned on the naso-occipital axis at a distance to the cyclopean eye that varied slightly between subjects (head-fixed condition, 32–41 cm; world-fixed condition, 129–134 cm). LEDs were flashed for 0.5, 4, or 100 ms. Timing precision of LED onset and offset (0.1 ms or better) was verified by recording the input signal of the LED at 50 kHz.
Eye-movement measurements.
We measured two-dimensional eye movements of the right eye with the double-magnetic induction technique (Bour et al., 1984; Bremen et al., 2007) using oscillating magnetic fields at 30, 48, and 60 kHz generated by three pairs of orthogonal coils (0.77 × 0.77 m) inside the vestibular stimulator. The horizontal, vertical, and frontal eye-position signals were amplified, demodulated by tuned lock-in amplifiers (model PAR 128A; Princeton Applied Research), low-pass filtered (150 Hz, custom-built fourth-order Bessel), and subsequently sampled at 500 Hz per channel (1401 Plus, using Spike 2 software; Cambridge Electronic Design) for storage on the hard disk of the computer (Precision 360; Dell Computer Company) together with the chair position.
Conventions: coordinate system
We express the coordinates of visual target locations and eye-in-head positions in a double polar coordinate system, in which the origin coincides with the center of the head (Knudsen and Konishi, 1979). In this system, the left/right azimuth coordinate, α, is defined as the angle within a horizontal plane with the vertical midsagittal plane. The up/down elevation angle, ε, is defined as the angle within a vertical plane with the horizontal plane through the subject's eyes. The straight-ahead position is defined by [α, ε] = [0, 0]°.
Experimental paradigms
Subjects participated in six different experiments (two paradigms with three target durations) that were performed on different days. The order was varied over subjects. In three world-centered experiments, the visual targets were stationary in space, whereas in the other three head-centered experiments, the targets rotated along with the subject. As a precaution, we avoided the potential use of binocular vision and depth estimation by blindfolding the right (measured) eye, for all experiments except for the 4 ms head-fixed targets, for which only subject MK was blindfolded. JO was never blindfolded, because his amblyopia precluded the use of any visual depth-related cues.
Calibration.
A calibration run preceded each experimental run, in which the subject fixated 37 (head-fixed condition) or 49 (world-fixed condition) LEDs that covered the oculomotor range. At fixation, the subject pressed a joystick, which triggered 50 ms sampling of horizontal, vertical, and frontal eye-position signals. These data were used for offline calibration of the eye-position signals. As described above, the distance between the head and LED array, and thus the eccentricity of the LED, varied slightly across subjects, resulting in different calibration ranges from 29 to 40°.
Static condition.
We assessed the subject's baseline visual-localization behavior to the target flashes in a static run presented at the beginning of the experimental sessions with the head-fixed targets. An LED was flashed for 0.5, 4, or 100 ms (as used in the different vestibular sessions) at an eccentricity of (approximately) 20° in one of eight randomly chosen oblique directions (±30, ±60, ±120, ±150°), where 0° denotes rightward and 90° upward. The targets were presented in a pseudorandom order with an interstimulus interval of 3.5 s, such that in total 96 targets (12 repetitions of 8 stimuli) were presented. The subject had to redirect gaze as fast and as accurately as possible to the perceived location of the visual target, keep gaze there for a moment, and then return to straight ahead. During localization trials, we did not present an initial fixation light at straight ahead.
Dynamic condition.
In the dynamic condition, the subject was rotated sinusoidally around the Earth-vertical axis at a frequency of ⅙ Hz, with a peak amplitude of 70°. To avoid discontinuities in velocity and acceleration at motion onset, angular velocity increased linearly over the first two sinusoidal periods during which no visual targets were presented. After these two periods, 96 targets were presented during 48 sinusoidal periods, at an interstimulus interval of on average 3 s. Subjects participated in three to four dynamic runs per condition.
We tested two conditions. (1) In the head-fixed condition, the LED array was attached to the chair. The same LEDs as in the static condition were used (12 repetitions of 8 stimuli). Stimuli were presented at pseudorandom times during the vestibular cycle. (2) In the world-fixed condition, the LED array was stationary in space and placed in front of the chair. Two LEDs (elevation, 11°; azimuth, 0° with respect to stationary straight-ahead) were presented randomly within the period of ±200 ms around peak chair velocity, during which the chair moved ∼28°. Because the position of the chair (and hence the head-in-space) varied with respect to the LEDs, the two LED locations resulted in various target relative to head locations, with initial azimuth components between −14° and +14° (left/right).
The subject's task was to make an eye movement toward the perceived location of the target as fast and as accurately as possible, to briefly fixate this position, and then return to the perceived head-centered straight-ahead location. We gave no additional instructions regarding the reference frame (head-centered, world-centered, or otherwise) of the responses. Note that we neither presented a fixation light at straight ahead, nor did we present any practice trials preceding the experiments.
Data analysis
Calibration of eye-position data.
We determined the relation between raw eye-position signals and the corresponding LED positions by training two neural networks for the azimuth and elevation eye-position components, respectively (for details, see Goossens and Van Opstal, 1997b). The raw data of each run were calibrated with networks of the calibration run that were presented immediately before this run.
Saccade detection.
A custom-made Matlab (MathWorks) program detected saccades and vestibular quick phases from the calibrated eye-movement signals offline by setting separate thresholds for eye velocity at saccade onset (70°/s) and offset (60°/s). We visually checked the saccade detection markings and made manual changes when deemed necessary. To differentiate between quick phases of vestibular nystagmus and goal-directed saccades, we required the goal-directed saccades to have a vertical component, because the visual targets were presented at different elevations, and the reflexive vestibular quick phases had a negligible vertical component. Responses with extremely short latencies were regarded as anticipatory and very long reaction times as inattentiveness of the subject. We therefore discarded saccades with latencies shorter than 80 ms and longer than 800 ms. Eye positions exceeding the head-centered calibration range of 29–40° (see above, Calibration) were also excluded. Correction saccades in darkness were very rare (0.73 ± 0.60%), and therefore we report only on the first goal-directed saccade in each trial.
Statistics.
For the static localization experiment we quantified the final eye-in-head positions in the azimuth (αRstat) and elevation (εRstat) direction by determining the optimal linear fit through the data:

 where αT and εT are actual target azimuth and elevation relative to the head, bstat and dstat are the biases (offset, in degrees), and astat and cstat are the gains (slope, dimensionless) of azimuth and elevation responses, respectively. Parameters were found by minimizing the mean-squared error (Press et al., 1992). From the linear fit, we also determined the correlation coefficient (r) between data and model prediction, the coefficient of determination (r2), and the SD of the residual error (σ).
where αT and εT are actual target azimuth and elevation relative to the head, bstat and dstat are the biases (offset, in degrees), and astat and cstat are the gains (slope, dimensionless) of azimuth and elevation responses, respectively. Parameters were found by minimizing the mean-squared error (Press et al., 1992). From the linear fit, we also determined the correlation coefficient (r) between data and model prediction, the coefficient of determination (r2), and the SD of the residual error (σ).
Ideal static localization performance yields gains of 1.0 and biases of 0.0°. However, parameters astat, bstat, cstat, and dstat could deviate from the ideal values in an idiosyncratic way. To enable data pooling across subjects and conditions, we normalized the target locations with respect to the data obtained in the static localization condition for the 4 ms targets:

 These normalized target locations, THAz and THEl, were then used to perform regression on the dynamic localization responses of the vestibular stimulation experiments:
These normalized target locations, THAz and THEl, were then used to perform regression on the dynamic localization responses of the vestibular stimulation experiments:

 Because the vestibular stimulation only affected the horizontal eye-movement components and induced only horizontal head displacements, we do not present the regression results on the elevation data in detail.
Because the vestibular stimulation only affected the horizontal eye-movement components and induced only horizontal head displacements, we do not present the regression results on the elevation data in detail.
Modeling.
To determine to what extent the visuomotor system incorporated the intervening vestibular-induced eye and head movements during the reaction-time period, we performed a multiple linear regression analysis on the horizontal saccade components, because these were the components perturbed by the vestibular stimulation. The horizontal saccadic eye displacement (ΔG) was described as a linear combination of the horizontal initial target location on the retina (TR), the horizontal vestibular-induced eye displacement (ΔEH) in the head, and the horizontal passive displacement of the head in space (ΔHS), both between target onset and response onset (Eq. 1):

 in which a, b, and c are dimensionless response gains, and d is the response bias (in degrees). In this paper, we consider four potential spatial updating models to explain visual-evoked saccade responses (Fig. 1, Table 1). In model I, full compensation of eye- and head-displacement signals corresponds to a world-centered target representation. In model II, only the vestibular-induced change in eye position is accounted for and the target remains in an updated head-centered reference frame. Model III only incorporates the passive change in head orientation, whereas the visuomotor system is unaware of the intervening vestibular nystagmus. Finally, in model IV, none of the intervening movement signals are accounted for and the target remains in its initial eye-centered reference frame. Table 1 summarizes the theoretical coefficients that correspond to each of the models.
in which a, b, and c are dimensionless response gains, and d is the response bias (in degrees). In this paper, we consider four potential spatial updating models to explain visual-evoked saccade responses (Fig. 1, Table 1). In model I, full compensation of eye- and head-displacement signals corresponds to a world-centered target representation. In model II, only the vestibular-induced change in eye position is accounted for and the target remains in an updated head-centered reference frame. Model III only incorporates the passive change in head orientation, whereas the visuomotor system is unaware of the intervening vestibular nystagmus. Finally, in model IV, none of the intervening movement signals are accounted for and the target remains in its initial eye-centered reference frame. Table 1 summarizes the theoretical coefficients that correspond to each of the models.
Theoretical regression coefficients of Eq. 6 for the four models
Regression parameters were determined by applying the least-squares error criterion. We applied the bootstrap method to obtain confidence limits for the optimal fit parameters in the regression analysis. To that end, 1000 datasets were generated by random selection of data points from the original data, which yielded 1000 different fit parameters. The SD of these fit parameters was taken as an estimate for the confidence levels of the parameter values obtained in the original dataset (Press et al., 1992).
To determine whether the variability of azimuth or elevation endpoint data for the different stimulus durations were significantly different, we applied the Kolmogorov–Smirnov (KS) test on the response error.
The effect of stimulus duration on the regression parameters ΔHS and ΔEH was determined with a one-way ANOVA with duration as factor.
Determining vestibulo-ocular reflex gain.
We fitted the chair-velocity and the horizontal eye-velocity signals over 40 cycles of each run by a sinusoid with a frequency of ⅙ Hz, with amplitude and phase as free parameters. The vestibulo-ocular reflex (VOR) gain was then determined as the amplitude of the eye velocity divided by the amplitude of the chair velocity. The VOR gains presented in Table 2 are averaged over all runs (∼23 runs per subject).
Average ± SD VOR gain of individual subjects
Results
Head and eye movements during the saccade reaction time
The design of the dynamic experiments was to ensure a considerable and variable amount of head and eye displacements during the reaction time of the subjects, who were instructed to make rapid eye movements toward brief visual flashes across the visual field. The bottom panels of Figure 2 show the latency distributions pooled over all subjects and all stimulus durations for the three localization conditions (static, 223 ± 52.2 ms; head-fixed condition, 229 ± 65.5 ms; world-fixed condition, 242 ± 80.5 ms). There was a considerable amount of passive head displacement during the reaction time (Fig. 2, top): the mean is around 0 but with a large SD. In the experiments with world-fixed targets, the head displacement distributions were bimodal, because the world-fixed targets were always presented around maximal chair velocity and thus large head displacements dominated the distribution (see Materials and Methods). We verified that the near absence of small head displacements in the world-fixed experiments did not introduce a bias in the results, by also analyzing only large head displacement trials for the head-fixed target experiments (data not shown). The eye-displacement distributions in the middle panels (Fig. 2) show that the eyes were not stationary during the reaction time either. Although subjects were instructed to redirect their gaze toward the perceived straight ahead after the goal-directed response and to keep their eyes there, they were unable to do so because of the ever-present vestibular nystagmus and of a potential bias in their own percept of straight ahead. For the analysis of the responses, however, this variability in initial eye positions was immaterial, because we always calculated actual stimulus locations on the retina on the basis of real eye-in-head positions rather than on the intended positions.
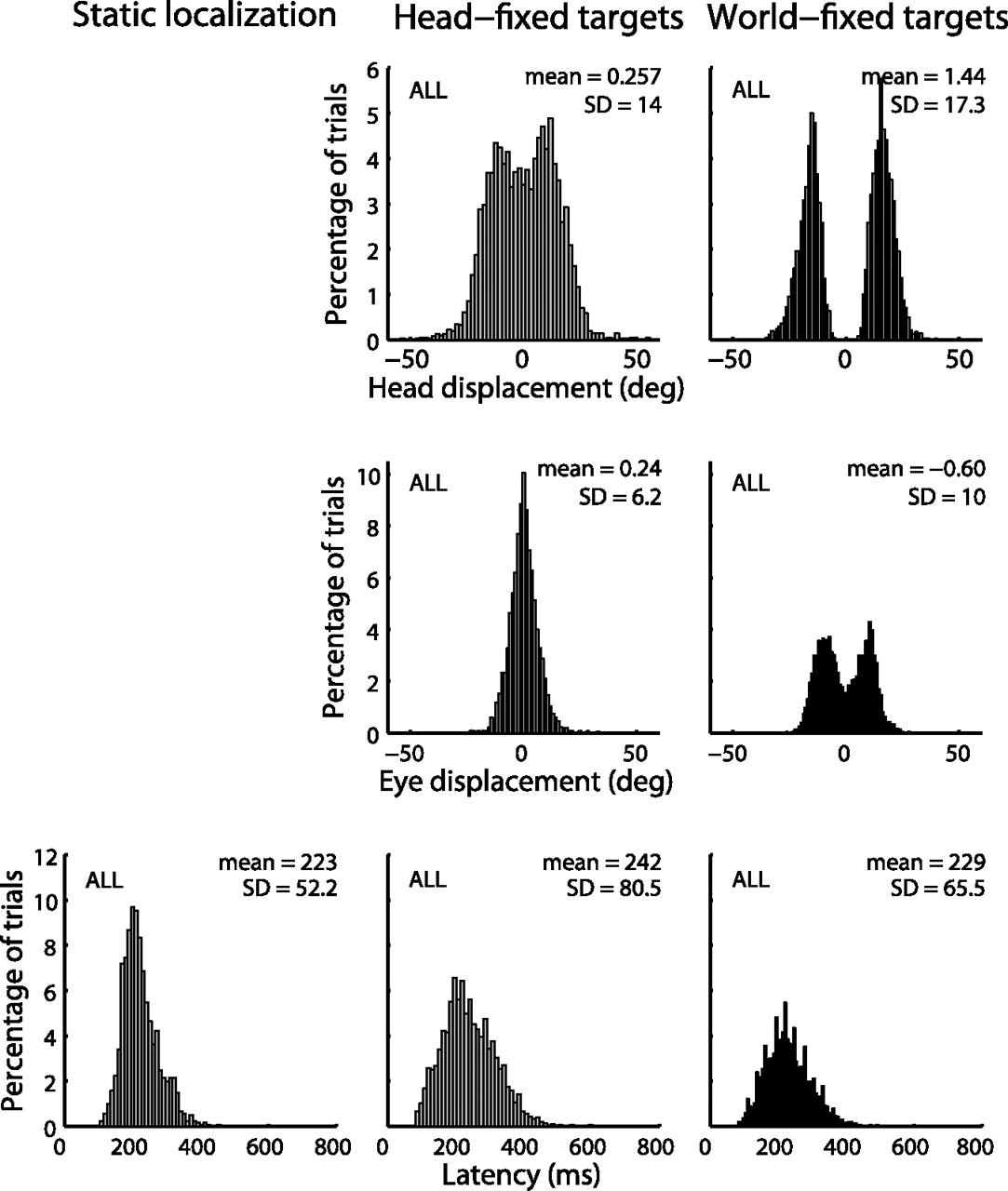
Distributions of head displacement and eye displacement during the response reaction times and reaction times (latency) pooled over the different target durations and over all subjects. Note the large range of eye and head displacements.
Static localization
To assess baseline visual localization performance for the brief flashes, subjects made saccadic eye movements without vestibular stimulation. The top two rows of Figure 3 show the results for subject MK to 0.5, 4, and 100 ms visual flashes. The subject was able to localize the visual flashes quite accurately (r2 = 0.98, σ ≈ 2°), and response variability did not depend on stimulus duration (KS test, p > 0.05). The bottom row of Figure 3 shows that all subjects accurately localized the visual targets (r2 = 0.96, σ < 2.9°) in the static condition. Note that, in these figures, target locations were normalized per subject (Eq. 3a, 3b). These results indicate that all visual flashes, including 0.5 ms, were well visible and localizable.

Standard localization behavior of subject MK to 0.5 ms (left), 4 ms (middle), and 100 ms (right) visual targets. The top row is a 2D response representation. The eye position at the beginning of the first goal-directed saccade (ERini, open circles) and the end points of the first goal-directed saccades (filled circles) are presented in head coordinates. Gray ellipses denote the 2 * SD of the end points. Normalized targets locations (see Materials and Methods) are presented by gray stars. The middle row shows the normalized linear regression results (Eqs. 3a, 3b) on azimuth response components of the same data as in the top row. The bottom row shows normalized linear regression results on azimuth responses pooled over all subjects. Data points were binned for graphical purposes (5° wide bins); symbol size and grayscale correspond to the likelihood of the responses.
Visual information on the retina
For correct spatial updating, the visuomotor system should know whether the stimulus was stationary in space or moved along with the head. This motion can in principle be deduced from the visual motion streak on the retina when appropriately compared with the eye, head, and body movements during stimulus presentation. Presumably, the patterns of visual motion streaks on the retina would differ for world-fixed and head-fixed targets. This can indeed be readily verified for the 100 ms target flashes in Figure 4A (bottom), which shows the reconstructed visual movement excursions on the retina during the vestibular slow phases of subject AK, which, for graphical purposes, were all aligned with the center of the plot (the actual streaks were scattered across the retina, because the initial eye position was never aligned with the stimulus location). Note that, if the VOR would be perfect (gain = 1.0), there would be no motion on the retina when the target is stationary in space, because the eye-in-space would be stationary too. A head-fixed target would then yield maximum motion on the retina in the direction of head motion. However, because the gain of the VOR did not reach the optimal value (Table 2), motion of the world-fixed targets resulted to be opposite to the direction of head motion, whereas retinal motion was in the same direction, but at lower speed, as the head for head-fixed targets. In Figure 4A, this is visible for the rightward (black) and leftward (gray) directions of the passive head-in-space movements. For the short-duration stimuli, however, the visual motion streak resulted to be very small (for 0.5 ms, 0.00 ± 0.01°, maximum of 0.19°; for 4 ms, 0.01 ± 0.08°, maximum of 0.77°). Figure 4A (middle and top rows) shows the visual streaks on the same scale as the 100 ms flashes, as well as on expanded scales (which show essentially the same patterns as for the 100 ms stimuli). Given the extremely small retinal excursions for the briefest stimuli, it is highly unlikely that these cues could have been used to discriminate target motion relative to the head from target movement relative to space. Figure 4B shows the average retinal motion streaks pooled over all subjects. The data show a consistent trend for all subjects: only the 100 ms stimuli could have provided a reliable dissociation of head-fixed and world-fixed targets during vestibular stimulation.

A, Retinal motion streak patterns for 0.5, 4, and 100 ms flashed targets during vestibular stimulation (subject AK) for leftward (gray) and rightward (black) chair rotation. For graphical purposes, the lines show the visual motion streaks relative to stimulus onset position. The actual streaks were scattered across the retina, because the initial eye position was never aligned with the stimulus location. Traces with quick phases are removed for clarity (21.8 ± 11.6%). The insets show a zoomed view. Note opposite retinal motion patterns for head-fixed and world-fixed targets. B, The average retinal motion streak with SD (error bars) of traces without quick phases of all subjects pooled.
Dynamic localization of head-fixed targets
The top two rows of Figure 5 show subject MK's localization performance for head-fixed targets during vestibular stimulation, with responses represented in a head-fixed reference frame. Accurate localization would mean that the visuomotor system would note that targets were indeed rotating along with the head; responses should scatter near the normalized target locations (gray stars; top panels) and lie around the identity line of the stimulus–response plots (middle panels). On average, localization responses (filled circles) were close to the target (slope close to 1 and bias close to 0). The horizontal scatter (σ), however, was larger than in the static condition (Fig. 3) (KS test, p < 0.05 in five subjects), and it decreased systematically with stimulus duration because scatter was smallest for the 100 ms stimuli (KS test, scatter 0.5 ms > scatter 4 ms, p < 0.05 in five subjects; scatter 4 ms > scatter 100 ms, p < 0.05 in five subjects). The bottom row of Figure 5 shows a similar trend when localization responses are pooled over all subjects. Also the scatter in response elevation was larger than for the static condition (KS test, p < 0.05 in five subjects) (data not shown). Note also the large variability in initial eye positions (open circles) as a result of the vestibular nystagmus.

Dynamic localization behavior of subject MK (top rows) and all subjects pooled (bottom row) to 0.5 ms (left), 4 ms (middle), and 100 ms (right) head-fixed visual targets, presented in head-fixed coordinates. Same conventions as in Figure 3.
Dynamic localization of world-fixed targets
The top row of Figure 6 shows the dynamic localization behavior of subject JO to world-fixed targets; responses are represented in world coordinates. If the visuomotor system would detect that targets were indeed stationary in space, responses should scatter around the unity line in the stimulus–response plot. For the shortest stimuli of 0.5 and 4 ms, this was clearly not the case. Responses showed a large variability (exceeding variability of the stationary condition: KS test, p < 0.01 in all subjects) and a low correlation between normalized stimulus azimuth and response. For the 100 ms stimuli, response variability was much lower (KS test, scatter 4 ms > scatter 100 ms, p < 0.05 in five of six subjects), and the stimulus–response correlation was higher than for the short stimuli. Thus, for the long-duration stimuli, spatial updating may have occurred (for a more detailed analysis, see below). The same pattern is observed in the localization data pooled across subjects (Fig. 6, bottom row). The response variability in elevation was slightly larger than for static localization for the 4 and 100 ms targets (KS test, p < 0.01 in five of six subjects) but not for the 0.5 ms flashes (KS test, p > 0.05 in four of six subjects) (data not shown).

Dynamic localization of subject JO (top row) and all subjects pooled (bottom row) to 0.5 ms (left), 4 ms (middle), and 100 ms (right) world-fixed visual targets, presented in world-fixed coordinates. Same conventions as Figure 3.
Testing spatial updating models
To determine which of the different updating models (see Introduction, Materials and Methods, and Fig. 1A) would best describe the dynamic responses, we first applied the ideal regression coefficients of Table 1 to the pooled intervening head- and eye-movement data shown in the distributions of Figure 2 to predict the associated saccadic eye displacements. Figure 7 plots the measured versus the predicted horizontal saccade components for the four spatial updating models in the head-fixed stimulus condition. The model that best describes the data should yield the highest coefficient of determination (r2) and the smallest residual variance (σ2). For the 4 and 100 ms stimuli, the results indicate best performance for the head-centered model (II), which suggests that the goal-directed saccade incorporated the intervening eye displacement and at the same time ignored the intervening head displacement. This was the appropriate response because the targets were indeed head fixed. However, the retinocentric model (IV) best predicted the responses to the 0.5 ms stimuli, which indicates that the saccades incorporated neither the intervening passive head movements nor the vestibular-induced eye displacements for these very short flashes.

Measured saccade amplitude in azimuth for the four models described in Materials and Methods (columns) plotted against predicted saccade azimuth of head-fixed targets; data pooled for all subjects. Rows correspond to different stimulus durations. Data points were binned for graphical purposes (10° wide bins); symbol size and grayscale correspond to log-likelihood of the responses. Dashed gray line shows linear regression results on the individual responses. Coefficients of determination (r2) and SD of the errors to the corresponding model (σ) are given in the bottom right corners of each subplot. If the model would predict the subject's responses perfectly, responses would fall on the unity line and r2 = 1. The gray-boxed panels have the highest coefficient of determination between predicted and response saccade azimuth. Model II, presented in gray font, is the appropriate model.
To test for the significance of the seemingly small differences, we performed KS tests on the cumulative error distributions between measured versus predicted saccades. Models II (appropriate updating into head-centered coordinates) and IV (no spatial updating) by far outperformed the other two models (highest correlations and smallest variances; KS test, p ≪ 10−4). Also the differences between models II and IV were significant for the three stimulus durations: for the 0.5 ms flashes, model IV outperformed model II (KS test, p < 0.001), whereas for the 4 and 100 ms flashes, model II was significantly better than model IV (KS test, for 4 ms, p < 0.001 and for 100 ms, p ≪ 10−4).
Figure 8 shows the results for the world-fixed stimulus condition in the same format as Figure 7. In this case, the world-centered model (I) now best describes the data for the 100 ms stimuli, which is the appropriate localization response. In contrast, the retinocentric scheme (model IV) best predicts the results for the 0.5 and 4 ms flashes, indicating no (or very little) updating for the intervening eye and head movements, despite the considerable variation in these variables (Fig. 2).

Measured saccade amplitude in azimuth for the four models described in Materials and Methods plotted against the predicted saccade azimuth of world-fixed targets; data pooled for all subjects. Same conventions as Figure 7. Model I, presented in gray font, is the appropriate model.
We compared the predictions of model I (updating in world-centered coordinates) versus model IV (no spatial updating; retinocentric), because these two models both outperformed by far the other two models. For the 0.5 and 4 ms flashes, model IV was significantly better than model I (KS test, for 0.5 ms, p ≪ 10−4 and for 4 ms, p ≪ 10−4), whereas for the 100 ms targets, model I significantly outperformed model IV (KS test, 100 ms, p < 0.001).
Together, the results indicate that only the long-duration visual stimuli, which may have provided a consistent dissociation of the retinal streak patterns for head-fixed versus world-fixed targets (Fig. 4), incurred appropriate spatial updating of targets into the head-centered or world-centered reference frame. In contrast, spatial updating was severely hampered, or even absent, when retinal motion was highly likely to be too small to be detected by the visual system. Because Figures 7 and 8 provide a preliminary analysis of the results, based on idealized versions of the different updating models, we next provide a quantitative regression analysis of the responses.
Multiple linear regression
To quantify the actual amount of compensation of intervening eye-in-head and passive head-in-space displacements within the saccade reaction time, we performed a multiple linear regression analysis on the subject's responses (Eq. 6) for the six dynamic stimulation conditions. Figure 9 shows the resulting gains of the individual subjects (thin lines) together with the averaged results pooled across subjects (bold) for the three stimulus durations and the two spatial target conditions (black, head-fixed targets; gray, world-fixed targets). The results show that, for all target flashes and for all subjects, the gain of the retinocentric target location (a) was close to the ideal value of a = +1.0 (left column, TR), indicating that all stimuli were well visible, also in the dynamic paradigm. For the 100 ms target durations (right-most values in each subplot), the gains for ΔHS (middle column) and ΔEH (right column) approximated their ideal values, which would be (b, c) = (0, −1), for the head-fixed targets (black) and (b, c) = (−1, −1) for the world-fixed stimuli (gray). Note, however, that the ΔHS gain did not reach the ideal value of −1.0, indicating an underestimation of the actual amount of head rotation. For the shortest stimuli of 0.5 ms (leftmost data points in each subplot), the ΔHS gain was even close to 0 for both the head-fixed and world-fixed stimulus conditions. The data show that the ΔHS gain for world-fixed stimuli depended significantly on stimulus duration (ANOVA, F(2,15) = 11.19, p = 0.001). For the head-fixed stimuli, this was not the case (ANOVA, F(2,15) = 0.16, p = 0.86), and values did not differ significantly from 0 (t test, p > 0.05). For 0.5 ms targets, the head-displacement gain did not differ between head-fixed and world-fixed targets (Wilcoxon's rank sum test, p = 0.39). For 4 and 100 ms targets, the world-fixed condition induced a stronger updating response than the head-fixed condition because the head-displacement gain was significantly larger for world-fixed flashes (Wilcoxon's rank sum test, for 4 ms, p = 0.04 and for 100 ms, p = 0.004) Also the eye-movement (ΔEH) gain for the shortest stimuli was strongly reduced to approximately −0.4, or less, for head- and world-fixed stimuli. The result for the 4 ms stimuli was typically close to that of 0.5 ms flashes, although intersubject variability was more pronounced for the intermediate stimulus duration. For both conditions, the ΔEH gain depended significantly on stimulus duration (ANOVA, F(2,15) = 11.96, p = 0.001 for head-fixed targets; F(2,15) = 4.55, p = 0.03 for world-fixed targets). The eye-displacement gain did not differ significantly between head-fixed and world-fixed targets (Wilcoxon's rank sum test, p = 0.09 for each stimulus duration).

Multiple linear regression results (Eq. 6) on the subject's responses to 0.5, 4, and 100 ms visual targets during passive whole-body rotation averaged across subjects for head-fixed (black) and world-fixed (gray) targets. Data points represent the regression coefficients of Equation 6 for individual subjects (thin lines) and their average (bold lines). Left column, Retinal target coefficient (TR); middle column, head-displacement coefficient (ΔHS); right column, eye-in-head position coefficient (ΔEH). Error bars represent 1 SD. The horizontal dotted lines at +1, 0, and −1 correspond to ideal regression values. For head-centered targets, [a, b, c]=[1, 0, −1]; for world-centered targets, [1, −1, −1] (Table 1). These ideal values are only approached for the 100 ms targets.
When using the regression coefficients (Eq. 6) (Fig. 9) to predict the saccade amplitude in azimuth, we compared the multiple linear regression model with each of the four ideal models described in Materials and Methods and Table 1 (Figs. 7, 8). The regression model describes the data with the highest correlation for all conditions (mean ± SD, r2 = 0.86 ± 0.07).
To summarize, appropriate spatial updating occurred for the long-duration stimuli (100 ms) only, because responses were directed toward the head-centered or world-centered location of the target, as required for accurate localization. Responses to the shortest targets, however, remained close to the initial retinocentric target coordinates, regardless of the reference frame of the target or the intervening movements.
Discussion
Summary
We investigated visual-vestibular integration in spatial updating of saccades. Our results show that updating relied on the integrity of visual information about the direction of target motion across the retina, as the only factor influencing spatial updating was visual flash duration. Long-duration flashes provided sufficient visual motion information (Fig. 4), for which the visuomotor system correctly incorporated passive intervening eye-head movements for world-fixed targets, and ignored head-movements for head-fixed targets. For very short flashes, however, the visual system could not reliably infer retinal stimulus motion, and thus could not dissociate whether stimuli moved with the head, or were stationary in space. In those cases the system tended to ignore intervening eye-head displacements altogether, and kept targets in eye-centered coordinates. We believe that this is a remarkable result, as in real life it is highly unlikely that visual stimuli are fixed to the retina.
Related studies
Vliegen et al. (2005) used dynamic visual double-steps by presenting a visual target flash (50 ms) during actively programmed eye-head gaze shifts, and showed that gaze shifts went toward the world-centered goal. These data are in line with our current findings for long-duration (100 ms) visual stimuli. Our current paradigm denied the gaze-control system access to corollary discharges of head movements and neck-muscle proprioception, by imposing head and eye movements through passive whole-body rotation. In line with earlier microstimulation studies in monkey midbrain superior colliculus (Mays and Sparks, 1980; Sparks and Mays, 1983), active programming of an intervening saccade is not required for accurate spatial updating. Presumably, the visuomotor system interprets the colliculus-induced signal as an internally programmed corollary discharge signal. This is supported by recent evidence that indicates a colliculus to frontal-eye-field pathway carrying an eye-displacement signal that could be used for spatial updating (Sommer and Wurtz, 2002). In line with this idea, microstimulation in the parapontine reticular formation evokes an intervening eye movement that is not compensated (Sparks et al., 1987), suggesting that the corollary discharge signal indeed arises upstream from the pons.
Our data further indicate that the visuomotor system needs adequate information about retinal stimulus motion. Retinal motion information during the high-velocity (>400°/s) gaze shifts in the Vliegen et al. (2005) study was probably sufficient for the visuomotor system to conclude that targets were stationary in space, as retinal streaks extended up to 30°. However, we cannot exclude the possibility that extremely brief flashes, like in our experiments, cannot be accurately localized after active gaze shifts either.
Visual localization performance during vestibular rotation was first studied by Van Beuzekom and Van Gisbergen (2002), who specifically instructed subjects to look at the head-centered location of 4 ms head-fixed flashes. Their results suggested compensation for the induced ocular nystagmus, but with increased horizontal endpoint scatter. However, since the data were not analyzed in terms of different updating models, it remained unclear to what extent subjects executed the task requirement, or whether a different instruction (“localize in world coordinates”) would have mattered. Our results show that instruction was probably immaterial, as subjects did not perceive a difference between head-centered vs. world-centered targets for these brief stimuli, and they responded in the appropriate reference frame for longer stimuli without specific instructions.
The whole-body movements in our paradigm had comparable dynamics as the intervening gaze shifts in smooth pursuit studies. Those experiments demonstrated that extraretinal information about the pursuit gaze-motor command is available to the saccadic system (Schlag et al., 1990; Herter and Guitton, 1998), as long-latency saccades (>200 ms) were directed to the world-centered location (Blohm et al., 2003, 2005; Daye et al., 2010). However, short-latency saccades (<175 ms) landed near the eye-centered location, and thus lacked spatial updating (McKenzie and Lisberger, 1986; Blohm et al., 2003, 2005; Daye et al., 2010), like for our briefest flash durations. In our experiments, however, we did not observe a latency-dependent effect (data not shown), as spatial updating varied exclusively with flash duration. Saccade reaction time was not a factor for spatial updating in the double-step saccade paradigm either (Goossens and Van Opstal, 1999; Vliegen et al., 2005). Note that the brief visual flashes in our experiment did not induce smooth-pursuit eye movements, as the brief target flashes appeared at unpredictable locations and never fell on the fovea. Besides, we did not use a visual fixation light to cancel the VOR.
Underestimation of head rotation
While visual target localization during active saccadic eye-head gaze shifts is typically accurate (Vliegen et al., 2005), passive head displacements appear to be slightly underestimated (Fig. 9) (Blouin et al., 1995a,b, 1997, 1998; Israël et al., 1999; Li et al., 2005; Klier et al., 2006; this study). During active head movements, the brain has access to various sources of information about self-movement: vestibular, neck-muscle proprioception, corollary discharges, efference copies, and retinal motion signals. During passive whole-body rotation, however, only vestibular and, in our paradigm, retinal motion signals are present. Possibly, the underestimation of head displacement could be related to an incomplete VOR gain (Table 2), in combination with the absence of supporting evidence from proprioceptive and efferent signals.
Proprioception is indeed used in target updating (Blouin et al., 1998). For example, neck-muscle vibration causes illusory motion of foveated targets (Biguer et al., 1988), and vibration of monkey dorsal neck-muscles shifts memory-guided saccade endpoints upwards (Corneil and Andersen, 2004).
The vestibular labyrinths are also involved in spatial updating: their surgical ablation severely compromises accurate updating of monkeys during yaw rotations (Wei et al., 2006). However, these deficits recover over time, suggesting that other signals (e.g., tactile, or body-proprioceptive cues) may take over the function of the vestibular apparatus.
We believe that perceptual learning (Israël et al., 1999) could not have played a role in our experiments, as subjects made automatic, short-latency saccade responses under open-loop conditions, and they were not instructed to respond in a particular reference frame. Moreover, their awareness of actual eye-in-head orientation was relatively poor, considering the substantial scatter in initial eye positions, despite the explicit instruction to look at straight ahead after the response.
No updating of extremely brief stimuli
The only way to dissociate the head-centered and spatial reference frames in our experiment was to deduce stimulus motion from the retinal target movement, appropriately combined with intervening eye- and head-movements. It is quite remarkable that the system could distinguish head-fixed vs. world-fixed targets. As the VOR attempts to stabilize the retinal image, stimuli should on average be stationary on the retina when stable in space (the typical visual world condition), and move at head velocity when head-fixed (a rather unlikely situation in the real world). For long-duration flashes, retinal motion patterns were indeed different for the two conditions, but did not conform to the typical real-world situation with an optimal VOR: head-fixed targets moved along with the head at a lower speed, whereas world-fixed targets moved in the opposite direction (Fig. 4). Rather than assuming that the stimulus was also moving through space, the system generated the appropriate oculomotor responses, despite the unlikely stimulus in the head-fixed condition, and the non-ideal VOR (Table 2).
That short-duration stimuli were not updated cannot be explained by poor stimulus visibility, because localization accuracy and precision in the stationary condition did not depend on stimulus duration (Fig. 3). Furthermore, the retinal target coefficient during vestibular stimulation was close to ideal for all flash durations (Fig. 9). Perceptually, these extreme brief flashes seemed indistinguishable from the 4 ms flashes. This may be explained by the fact that neural activity in the central visual system to brief visual probes is prolonged to several tens of ms (Duysens et al., 1985). Since the retinal motion streak at the visual periphery for these short flashes (Fig. 4) was far below the retinal spatial resolution, the system could not deduce stimulus motion with respect to the eye to update targets in the appropriate reference frame. In line with this, Festinger and Holtzman (1978) showed that poorly-defined visual smear hampers perceptual estimates of stimulus motion. Our data show that under those conditions the visuomotor system tends to keep targets in eye-centered coordinates, which have been suggested to be the coordinates also used by visual memory (Baker et al., 2003). This default strategy is surprising for several reasons. First, the integrity of the extraretinal signals was the same for all stimulus conditions, so that the visuomotor system did have adequate information about intervening self-movements of eyes and head. Second, it is highly unlikely in daily life that visual stimuli move along with the eyes or head. Thus, one would rather expect a default strategy to localize targets in world-centered coordinates, since all signals required for this transformation (Eq. 6) were available. The only difference between the six conditions, not captured by the different spatial-updating models, is the amount and direction of retinal motion during stimulus presentation. This strongly suggests that during passive vestibular stimulation the integrity of this signal is required to induce spatial updating. Whether this conclusion also holds for actively generated gaze shifts remains to be studied.
Footnotes
This research was supported by the Radboud University of Nijmegen (A.J.V.O., A.C.M.K., D.C.P.B.M.V.B.) and Netherlands Organization for Scientific Research Project Grant 805.05.003 ALW/VICI (A.J.V.O.). We thank Hans Kleijnen, Ger van Lingen, and Stijn Martens for valuable technical assistance.
- Correspondence should be addressed to John Van Opstal, Radboud University Nijmegen, Donders Institute for Brain, Cognition and Behaviour, Department of Biophysics, Geert Grooteplein 21, 6525 EZ Nijmegen, The Netherlands. j.vanopstal{at}donders.ru.nl





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}